

发现大量的 SYN_RECV
几个月前有一次线上某个服务出了点问题,登到服务器上查一查,发现后端服务 CPU 跑满,前端调用无响应,查看端口时发现后端服务端口有大量的 SYN_RECV 状态的连接。
当时先查出后端服务出现内存溢出,导致半卡死,于是优先重启了服务恢复服务正常运行。关于为什么出现大量 SYN_RECV 连接并没有更细致去排查,而且后续基本没有收到有其他问题的反馈,也就一直没有去分析。
最近倒是闲来无事,对服务端口进行了一些抓包,后续会更几篇抓包分析,做个记录也做个分享。
因为一时好奇心(当然也因为计算机网络的知识早已还给了老师),在查询 SYN_RECV 的时候还是重新学到了一些 TCP 相关的细节知识,还有 Nginx、Tomcat 等服务器应用需要注意的优化项。
TCP 中的 SYN_RECV 状态
SYN_RECV 状态只会出现在 TCP 连接创建时的服务端,服务端在收到客户端发出的 SYN 包后,返回 SYN/ACK 包,此时端口状态将会由 LISTEN 变为 SYN_RECV,也就出现了一个半连接(half-open connection)
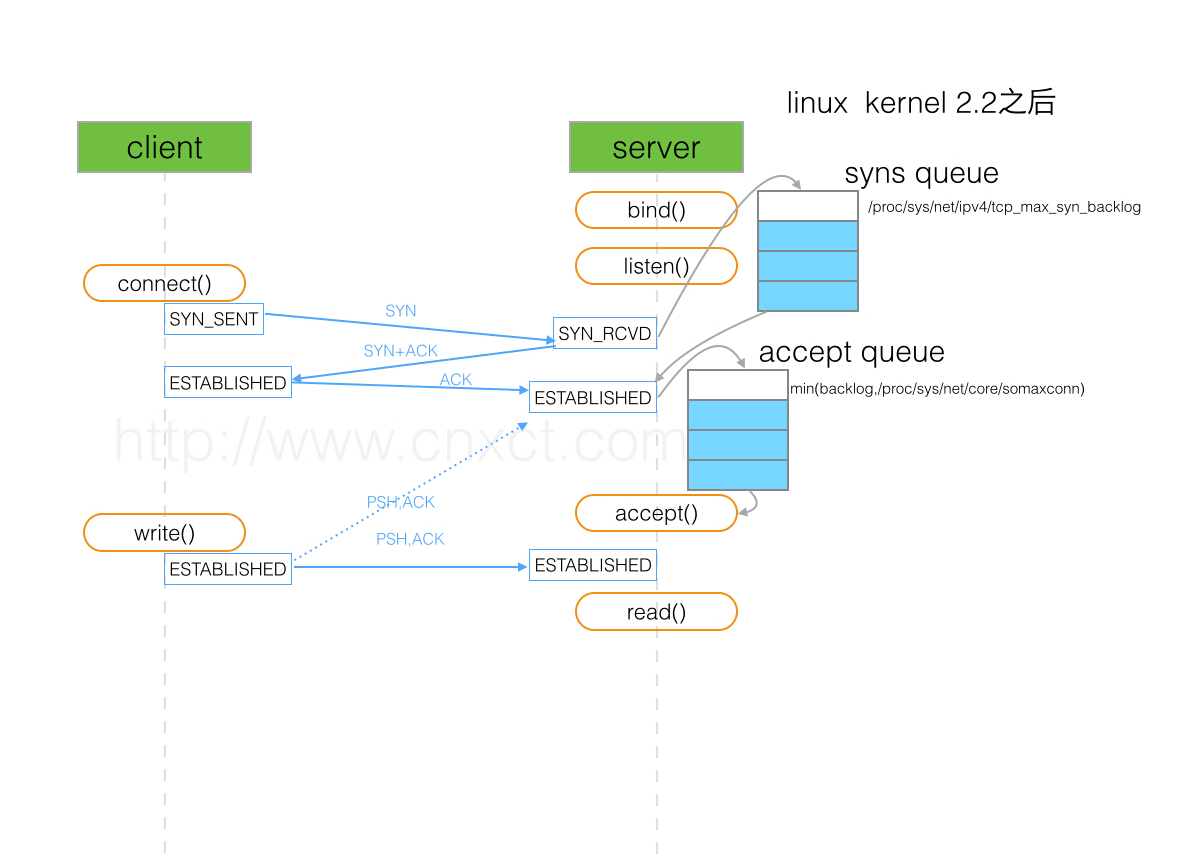
这里附一张很直观的图,摘自博客《TCP SOCKET中backlog参数的用途是什么?》,这篇博客也强烈推荐看一遍。
出现大量 SYN_RECV 状态的端口,从流程上讲,应该是有四种可能:
1. 服务端返回 SYN/ACK 包,但失败
2. 服务端返回 SYN/ACK 包,但客户端没收到
3. 服务端返回 SYN/ACK 包,客户端收到了,但没返回 ACK 包
4. 服务端返回 SYN/ACK 包,客户端收到了,返回 ACK 包,服务端没收到
对1、2、4,大概都是服务端的故障导致的;
对3,有一个 SYN flood 攻击的说法,就是攻击方只发 SYN 包,不回 ACK 包,将服务端的大量端口占用,堆满 SYN 队列,使其不能响应正常的服务。
几个系统配置
下面的英文概述来自官方文档 ip-sysctl.txt 和 net.txt ,中文概述来自华为云的一篇帖子
net.ipv4.tcp_max_syn_backlog
file: /proc/sys/net/ipv4/tcp_max_syn_backlog
variable: net.ipv4.tcp_max_syn_backlog
tcp_max_syn_backlog - INTEGER
Maximal number of remembered connection requests (SYN_RECV), which have not received an acknowledgment from connecting client. This is a per-listener limit.
The minimal value is 128 for low memory machines, and it will increase in proportion to the memory of machine. If server suffers from overload, try increasing this number.
Remember to also check /proc/sys/net/core/somaxconn
A SYN_RECV request socket consumes about 304 bytes of memory.该参数决定了系统中处于 SYN_RECV 状态的 TCP 连接数量。SYN_RECV 状态指的是当系统收到 SYN 后,作为 SYN+ACK 响应后等待对方回复三次握手阶段中的最后一个 ACK 的阶段。对于还未获得对方确认的连接请求,可保存在队列中的最大数目。如果服务器经常出现过载,可以尝试增加这个数字。
net.ipv4.tcp_synack_retries
file: /proc/sys/net/ipv4/tcp_synack_retries
variable: net.ipv4.tcp_synack_retries
tcp_synack_retries - INTEGER
Number of times SYNACKs for a passive TCP connection attempt will be retransmitted. Should not be higher than 255. Default value is 5, which corresponds to 31seconds till the last retransmission with the current initial RTO of 1second. With this the final timeout for a passive TCP connection will happen after 63seconds.
指明了处于 SYN_RECV 状态时重传 SYN+ACK 包的次数。
net.core.somaxconn
file: /proc/sys/net/core/somaxconn
variable: net.core.somaxconn
somaxconn - INTEGER
Limit of socket listen() backlog, known in userspace as SOMAXCONN. Defaults to 4096. (Was 128 before linux-5.4)
See also tcp_max_syn_backlog for additional tuning for TCP sockets.该参数定义了系统中每一个端口最大的监听队列的长度,是个全局参数。该参数和 net.ipv4.tcp_max_syn_backlog 有关联,后者指的是还在三次握手的半连接的上限,该参数指的是处于 ESTABLISHED 的数量上限。
listen(2) 函数中的参数 backlog 同样是指明监听的端口处于 ESTABLISHED 的数量上限,当 backlog 大于 net.core.somaxconn 时,以 net.core.somaxconn 参数为准。
net.core.netdev_max_backlog
file: /proc/sys/net/core/netdev_max_backlog
variable: net.core.netdev_max_backlog
netdev_max_backlog
Maximum number of packets, queued on the INPUT side, when the interface receives packets faster than kernel can process them.
当内核处理速度比网卡接收速度慢时,这部分多出来的包就会被保存在网卡的接收队列上,而该参数说明了这个队列的数量上限。在每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
关于 backlog
这里讲的是上面提到的系统参数 tcp_max_syn_backlog 设置的 backlog,从前面的图中可以看出,该值影响了一个端口能接收的半连接的个数,即 SYN queue 的长度。
在博客 《How TCP backlog works in Linux》 中讲到,因为服务端在端口变成 ESTABLISHED 状态前会有一个中间态 SYN_RECV,所以实现 TCP/IP 的系统自然就有两种选择:
1. 使用一个队列,同时存放半连接和全连接
2. 使用两个队列,分别存放半连接和全连接
在 Linux 系统中,采用的就是第 2 个方案(Linux 2.2 +),为半连接队列提供了一个系统参数,即 tcp_max_syn_backlog。 而全连接队列的大小由程序自己控制,参考 listen() 函数的第二个参数 backlog。
这个参数目前的理解,更多可能是用在防止 SYN flood 攻击上,稍微增大该值理论上来说也是可以提高服务器的高并发能力,可以接受更多的 TCP 连接请求。
此外还有 tcp_synack_retries 参数,如果遇到 SYN flood 攻击,减小该值也会降低服务器的压力。
关于 somaxconn
在之前学习 Nginx 的时候,关于系统层面的优化,只做了增大端口范围、增大 ulimit 限制等,结合上面的学习,注意到还有个参数要优化,就是 somaxconn,该值影响了一个端口能接收的全连接的个数。
somaxconn 是系统级别的调整,具体到 Nginx、Tomcat 等服务器程序,就像上一节中说到的,它们也要设置自己的 backlog(影响端口建立全连接个数)。
Nginx 优化
在 Nginx 的官方博客中也找到了关于此项的介绍:
- net.core.somaxconn
The maximum number of connections that can be queued for acceptance by NGINX. The default is often very low and that’s usually acceptable because NGINX accepts connections very quickly, but it can be worth increasing it if your website experiences heavy traffic. If error messages in the kernel log indicate that the value is too small, increase it until the errors stop.
增大这个参数,可以增加能成功连接到 Nginx 服务的 TCP 连接数,按系统配置,somaxconn 一般默认值为 512,所以 Nginx 对监听端口设置的待处理连接队列大小为 511(可见官方文档)。
增大 somaxconn 的大小后,同时也需要显式增大 Nginx 的配置,当 Nginx 的 backlog 大于系统的 somaxconn,明显则会以 somaxconn 为准生效:
server {
listen 127.0.0.1:12345 backlog=2048;
}
Tomcat 优化
Tomcat 中也有一个关于接收连接队列长度的配置参数 —— acceptCount,官方文档中的描述为:
The maximum queue length for incoming connection requests when all possible request processing threads are in use. Any requests received when the queue is full will be refused. The default value is 100.
就是说,在 Tomcat 的所有处理线程都在工作时,后续再进来的请求都会先放进这个队列,进行等待,当队列满时,之后的请求会被拒绝。
优化请注意
在博客《TCP SOCKET中backlog参数的用途是什么?》中,看到了博主用 Nginx + PHP 进行了测试:
1.如果后端服务(Nginx 的上游)backlog 设置过大
在后端服务业务处理缓慢时,堆积在全连接队列中的 TCP 连接有被客户端(Nginx)因超时而关闭的可能,此时 Nginx 会打印错误日志:
upstream timed out (110: Connection timed out) while reading response header from upstream
2.如果后端服务(Nginx 的上游)backlog 设置过小
Nginx 则可能出现不能连接成功的情况,错误日志为:
connect() failed (111: Connection refused) while connecting to upstream
还有一件事
只注意增大连接数还是不太够,Linux 系统下一个个 socket 连接也是一个个文件描述符,所以不仅需要调整 ulimit 限制中的 nofile,还要适当调整系统层面的文件描述符限制 —— sys.fs.file-max。
最后的疑问
关于 net.core.somaxconn 还有一些细节,想了一想,可能把自己绕进去了,很可能其实是自己对服务端的理解不对,这个问题先列在这,回头学清楚了再更新吧。
对于这个参数,好像有两种说法:
一是它限制了一个端口的监听队列长度,就是说握手成功后的连接,会在这个队列中等待服务端的处理线程取走进行处理;
另一个是它限制了一个端口上处于 ESTABLISHED 状态的连接数量。
那么问题就来了,建立成功的连接被处理线程取出处理时,这个连接不还是在 ESTABLISHED 状态吗?假设有10个处理线程,取走了 10 个连接进行处理,那队列中还可以继续累积 somaxconn 个连接,那这个端口上现在所有处于 ESTABLISHED 状态的连接个数不是已经变成了 somaxconn + 10 么?