

1 写在前面
Logstash 被称为数据处理管道,由输入插件、过滤器插件、输出插件三部分构成,在常规的配置下,一个 Logstash 实例中只有一个管道运行,从 6.0 版本后,官方逐渐推出了一些多管道的配置,能够在一个 Logstash 实例中启动多个管道执行。
2 版本说明
Logstash 6.3.0 以上
3 配置方案
3.1 单管道配置
先讲运行单个 Logstash 实例的情况,在最基本的单个管道配置下,又有以下几种方案来实现不同的输出方式。
3.1.1 单输出插件
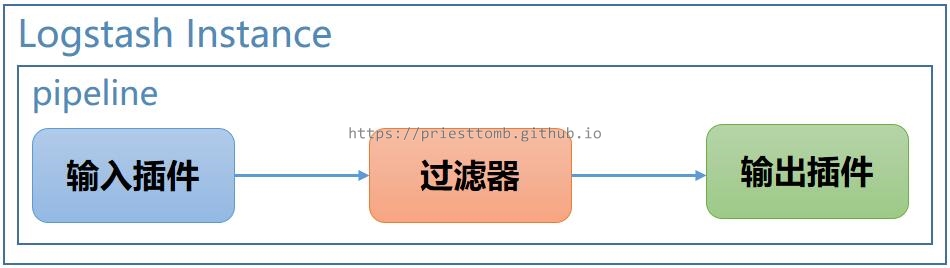
显而易见,如果只配置一个输出插件,Logstash 便只能向一个地方输出结果。
一份简略的配置如下:
input {
file {
path => "/tmp/test.log"
}
}
filter {
json {
skip_on_invalid_json => true
source => "message"
}
}
output {
stdout {}
}
3.1.2 多输出插件
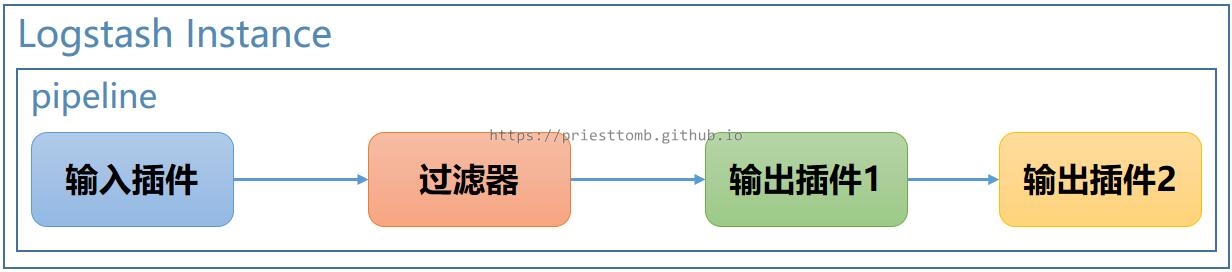
更进一步,如果配置多个输出插件,Logstash 运行正常的情况下,就能依次向多个地方输出结果。
为什么说运行正常的情况下?因为前一个输出插件如果出了意外,导致消息不能被正常处理,后面的插件就不能继续收到消息,所以这样的方式配置多个输出插件时,插件之间会存在相互影响。
一份简略的配置如下:
input {
file {
path => "/tmp/test.log"
}
}
filter {
urldecode {}
}
output {
http {
method => "get"
url => "http://127.0.0.1:8080/test"
}
stdout {}
}
3.1.3 条件输出
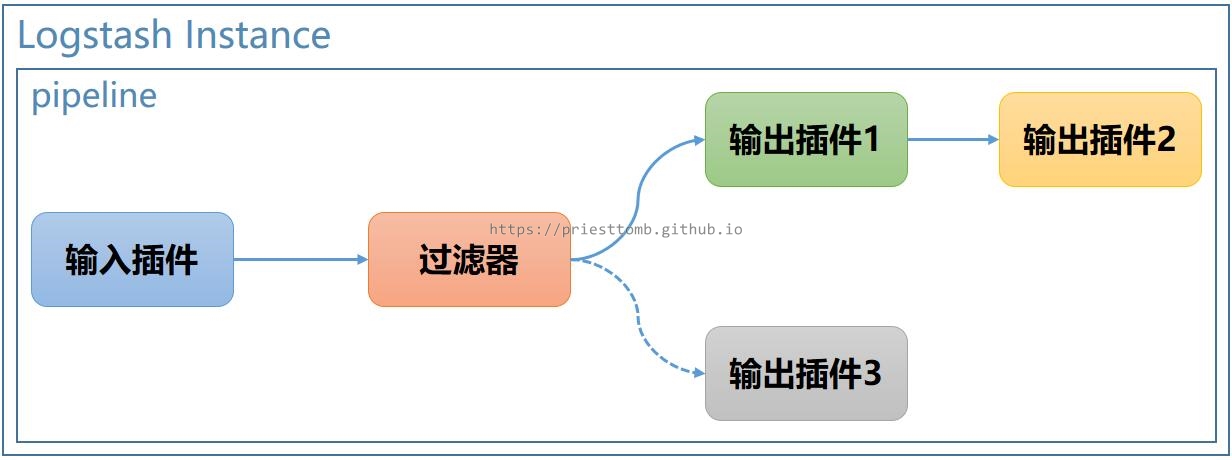
如果需要根据不同的情况,执行不同的输出逻辑,则可以在配置文件中使用 if…else… 语句实现。
一份简略的配置如下:
input {
file {
path => "/tmp/test.log"
}
}
filter {
json {
skip_on_invalid_json => true
source => "message"
}
}
output {
if [testParam] == "http" {
http {
method => "get"
url => "http://127.0.0.1:8080/test"
}
stdout {}
} else {
tcp {
host => "192.168.10.123"
port => 9999
}
}
}
3.2 多管道配置
在上一节单管道配置的基础上,现在可以实现单个 Logstash 实例运行多个管道,其中每个管道的配置跟上述单管道一致,这里就不再赘述,主要讲讲多管道的几种模式。
官方在 6.0 版本时推出了 multiple-pipelines 的功能,让 Logstash 能在一个实例内同时启动多个管道;之后又在 6.3 版本时推出了 pipeline-to-pipeline 的功能,让同一个 Logstash 实例内的不同管道间可以产生逻辑关系。
注意,多管道的使用必须使用 pipelines.yml 文件,这个配置文件中的配置有两点要注意,首先要指定不重复的 pipeline.id,其次要说明每个管道的插件配置,可以使用 path.config 指定插件配置文件的路径,也可以使用 config.string 直接把插件的配置写在该 pipelines.yml 文件中。而其余的配置,都跟 logstash.yml 中一样。
同时,启动 Logstash 时不再需要使用 -f 参数指定专门的配置文件,它会默认使用 pipelines.yml 的配置启动。
3.2.1 多管道相互独立
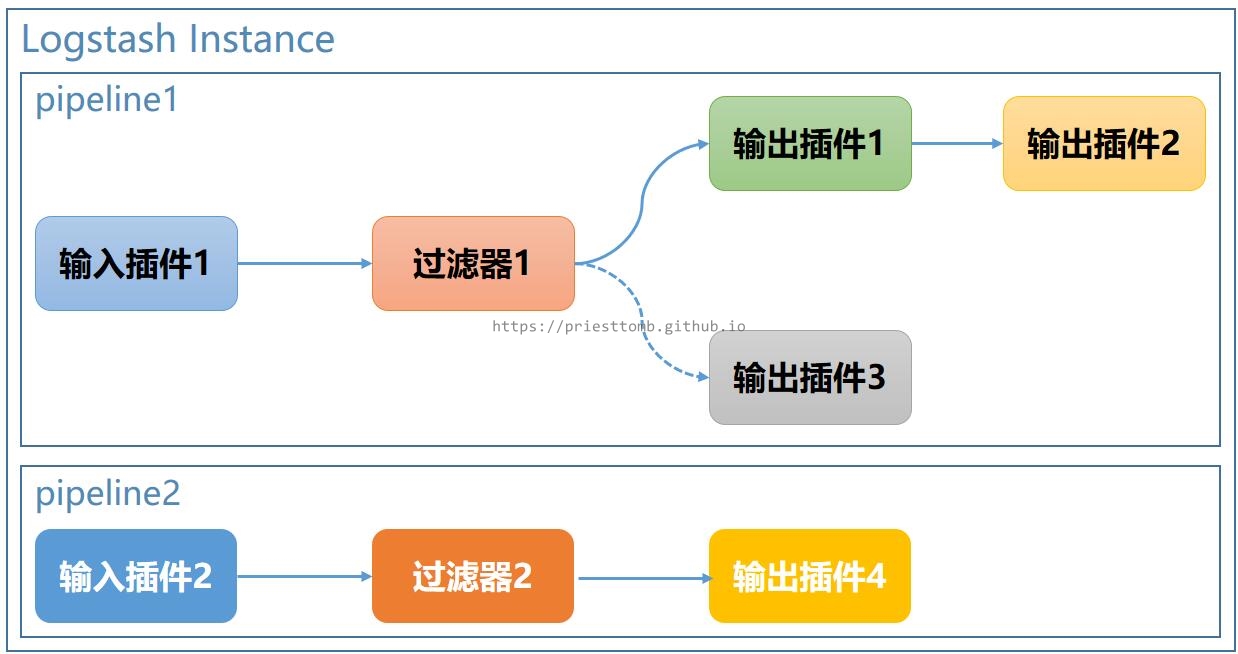
如果想在一个 Logstash 中启动多个管道,让它们各自运行,互不影响,在 6.0 版本后已经可以实现。
官方文档给的一份示例配置如下:
- pipeline.id: my-pipeline_1
path.config: "/etc/path/to/p1.config"
pipeline.workers: 3
- pipeline.id: my-other-pipeline
path.config: "/etc/different/path/p2.cfg"
queue.type: persisted
它使用插件配置文件 p1.config 启动了一个叫 my-pipeline_1 的管道,又设置这个管道的工作线程为 3 个;而同时又使用 p2.cfg 启动了一个叫 my-other-pipeline 的管道,设置这个管道的队列为持久化管道。
另外,官方还有一篇博客《如何创建易于维护和再利用的 Logstash 管道》介绍了这样的玩法:
- pipeline.id: my-pipeline_1
path.config: "<path>/{01_in,01_filter,02_filter,01_out}.cfg"
- pipeline.id: my-pipeline_2
path.config: "<path>/{02_in,02_filter,03_filter,01_out}.cfg"
简单来说,就是把各种输入插件、过滤器、输出插件拆分出来,成为不同的配置文件,再在 pipelines.yml 中使用 glob 表达式拼接它们,其中的好处是复用相同的插件配置,避免某一处问题修改还要到多个配置文件中去做。
3.2.2 多管道输出单管道
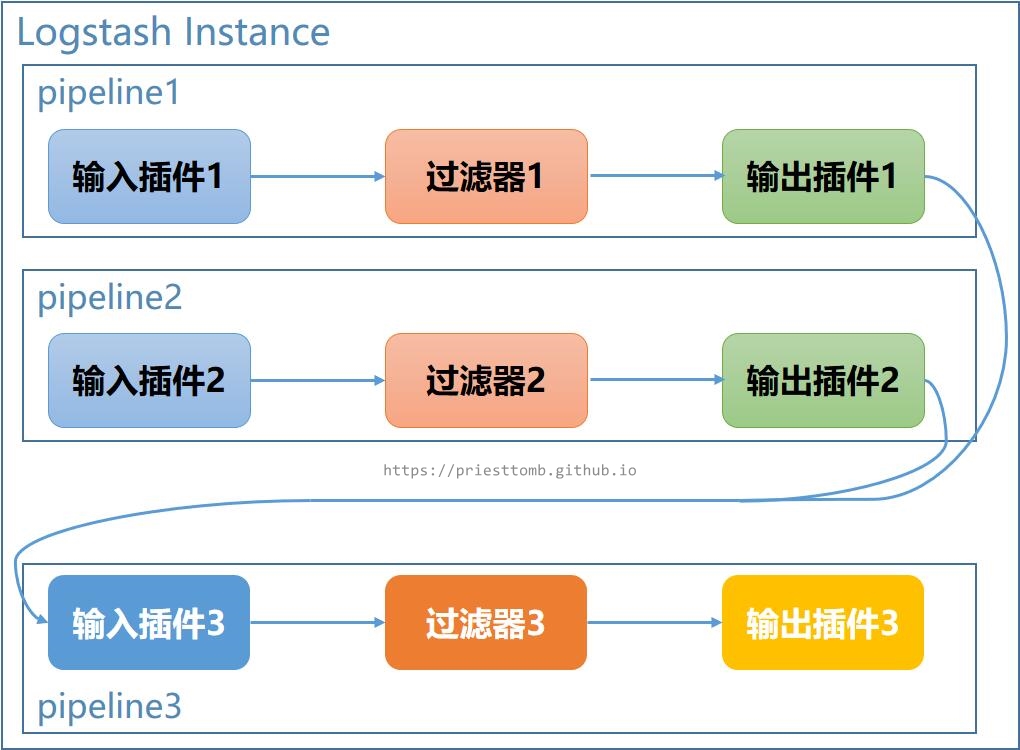
如果想要让事件(数据)在同一个 Logstash 实例上的多个管道内依次流动(处理),可以使用 pipeline-to-pipeline 功能,Logstash 提供了一个 pipeline 输出插件,可以将当前管道内的数据发送至 Logstash 实例内的虚拟服务上的指定虚拟地址,同时又提供了一个 pipeline 输入插件,根据虚拟地址,从虚拟服务中获取这些数据。
比如有多个不同来源的数据,分别经过各自的管道处理后,再流向通用的输出管道做最终处理,形成一种汇聚型的结构。
参考官方博客的一个示例配置:
- pipeline.id: beats
config.string: |
input { beats { port => 5044 } }
output { pipeline { send_to => [commonOut] } }
- pipeline.id: kafka
config.string: |
input { kafka { ... } }
output { pipeline { send_to => [commonOut] } }
- pipeline.id: partner
# This common pipeline enforces the same logic whether data comes from Kafka or Beats
config.string: |
input { pipeline { address => commonOut } }
filter {
# Always remove sensitive data from all input sources
mutate { remove_field => 'sensitive-data' }
}
output { elasticsearch { } }
它使用 beats 插件同时又使用 kafka 插件采集不同地方的数据,分别使用 pipeline 插件将所有的数据发送到 commonOut 这个虚拟地址,最后启动一个专门的管道,从该地址接收全部的数据,写入 elasticsearch。
3.2.3 单管道输出多管道
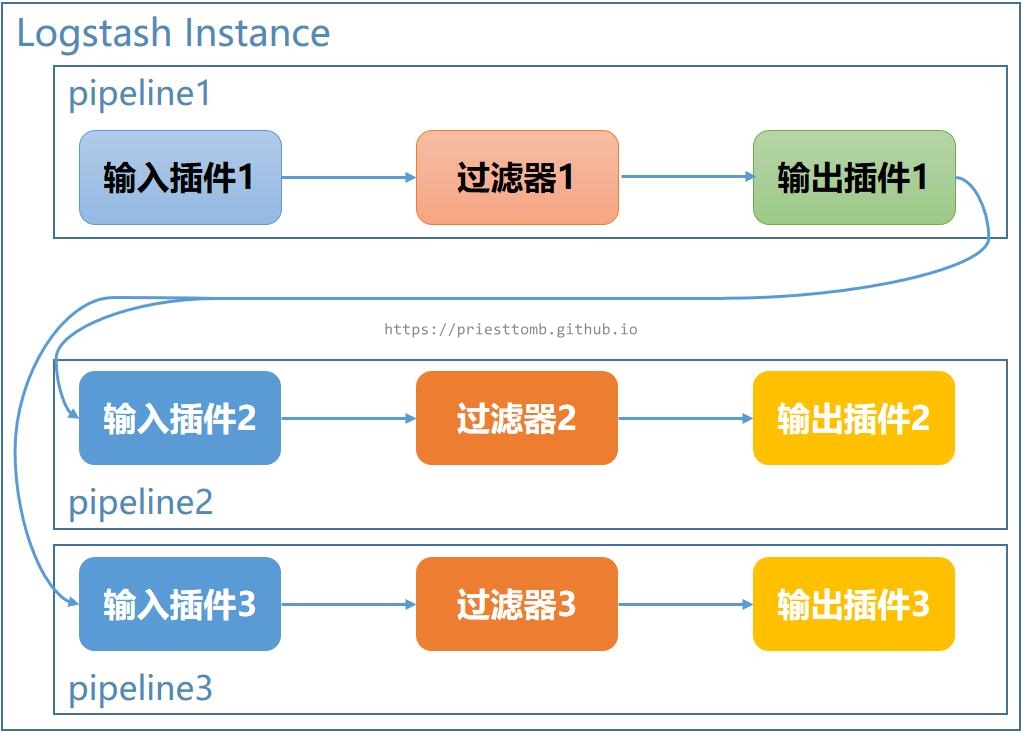
除了汇聚形式的管道搭配,还有各种分发形式的使用,从一个管道接收数据再传递到多个下游管道。
同样可以使用 if…else… 语句进行选择,究竟要发到哪个管道:
- pipeline.id: beats-server
config.string: |
input { beats { port => 5044 } }
output {
if [type] == apache {
pipeline { send_to => weblogs }
} else if [type] == system {
pipeline { send_to => syslog }
} else {
pipeline { send_to => fallback }
}
}
- pipeline.id: weblog-processing
config.string: |
input { pipeline { address => weblogs } }
filter {
# Weblog filter statements here...
}
output {
elasticsearch { hosts => [es_cluster_a_host] }
}
- pipeline.id: syslog-processing
config.string: |
input { pipeline { address => syslog } }
filter {
# Syslog filter statements here...
}
output {
elasticsearch { hosts => [es_cluster_b_host] }
}
- pipeline.id: fallback-processing
config.string: |
input { pipeline { address => fallback } }
output { elasticsearch { hosts => [es_cluster_b_host] } }
或者直接把数据发到全部下游管道:
- pipeline.id: intake
queue.type: persisted
config.string: |
input { beats { port => 5044 } }
output { pipeline { send_to => [es, http] } }
- pipeline.id: buffered-es
queue.type: persisted
config.string: |
input { pipeline { address => es } }
output { elasticsearch { } }
- pipeline.id: buffered-http
queue.type: persisted
config.string: |
input { pipeline { address => http } }
output { http { } }
3.3 多 Logstash 实例
除此之外,当然,还可以直接根据上述单管道或多管道的配置,直接启动多个 Logstash 实例。
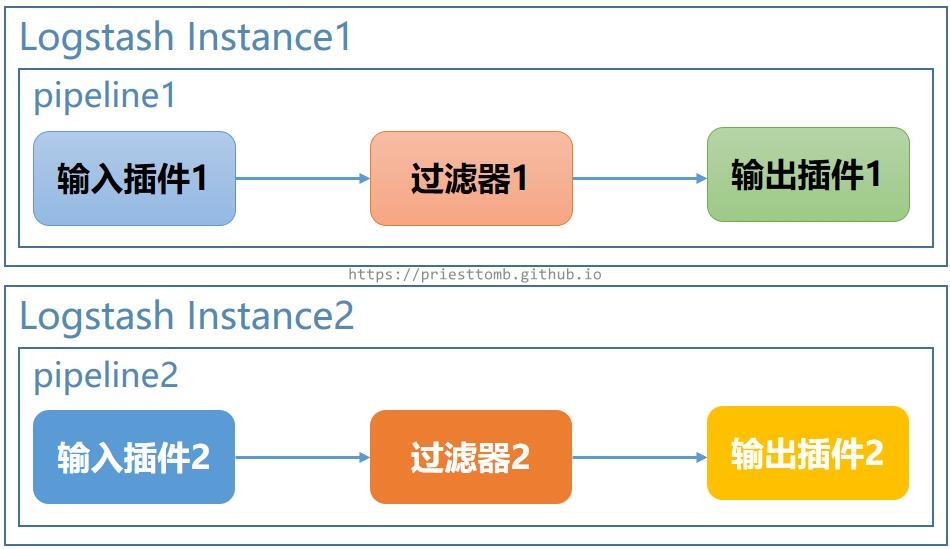
各实例间或毫无关联,或依然存在一定的逻辑关系,这里就不再举例了。
4 最后
Logstash 的应用可以说非常灵活,尤其是官方引入了多管道配置后,可以在一个 Logstash 实例内实现多个管道的搭配运行,方便了整个 Logstash 服务的管理。